
Let me tell you what I see most often when compliance teams first start working on EU AI Act documentation. They open Annex IV, read through it once, and come away with a vague sense that they need “some kind of technical document.” Then they either build a massive 150-page monster that covers everything twice, or they produce a thin four-pager that skims past the parts they didn’t understand.
Both approaches miss the point entirely. And both will fail a regulatory review.
Here’s what Annex IV is actually asking for: evidence. Not descriptions. Not promises. Evidence that your AI system was built with care, tested honestly, governed properly, and can be held accountable when something goes wrong. That’s a fundamentally different ask than most organizations have faced before — and it explains why so many early-stage documentation programs are going in the wrong direction.
The stakes are real. Get it wrong, and you’re looking at fines up to €15 million or 3% of global annual turnover[1], plus the possibility that regulators block your system from the EU market entirely. That’s before we even get to the reputational damage of being named in an enforcement action.
“The documentation requirement under the EU AI Act is not a box-ticking exercise. It is the mechanism through which regulators verify that an AI system was built responsibly and can be held accountable. Incomplete documentation is not just a compliance failure — it is evidence of governance failure.”
— European AI Office Guidance on Technical Documentation, 2025
This guide is written for legal counsel, compliance officers, technical writers, and engineering leads who need to translate Annex IV’s legal requirements into an actual documentation program — one that works in practice, not just on paper. I’ll cover every required element, explain what “sufficient” looks like for each one (regulators are more specific about this than most people realize), give you a complete template structure, and walk through the eight most common documentation mistakes that create serious legal exposure.
Before we go any further — if you haven’t yet confirmed whether your AI system qualifies as high-risk, start with our EU AI Act Classification Guide first. Documentation requirements only kick in once high-risk status is confirmed. No point building a dossier for a system that doesn’t need one.
If you’re confident you’re in scope: let’s build your documentation program.
This article is part of our broader EU AI Act Compliance Pillar Guide — the full pillar resource covering all requirements, timelines, and enforcement details.
The EU AI Act Documentation Framework: An Overview
Here’s the first thing worth understanding: Annex IV doesn’t require one document. It requires several — each serving a completely different purpose, aimed at a different audience, with different maintenance requirements. I can’t tell you how many times I’ve seen teams conflate all of this into a single “compliance document” that satisfies none of them properly.
Get the structure right from the start, and everything downstream gets easier. Get it wrong, and you’re constantly patching gaps.
Who Must Prepare Documentation?
The primary documentation obligation sits with providers — the organizations that develop, train, or place high-risk AI systems on the EU market. If you built it, you prepare the Annex IV dossier. Simple enough in principle, though the extraterritorial scope catches many teams off guard: it applies whether you’re EU-based or not, provided the system affects people in the EU.
But providers aren’t the only party with skin in the documentation game. Deployers — organizations using provider-built AI professionally — carry their own documentation obligations for how they implement and operate the system. More on that in Section 8.
There’s a grey zone worth flagging immediately. When a deployer makes a substantial modification to a high-risk AI system — fine-tuning it heavily on proprietary data, reshaping its intended purpose, integrating it in ways the original provider never designed for — they can cross the line from deployer to provider. And that means full Annex IV responsibility for the modified version. Every deployer team should honestly assess how much they’re actually changing what they deploy, before assuming the provider’s documentation covers them.
SME Simplified Documentation: What Smaller Organizations Can Do Differently
If you’re running a startup or a mid-size company, I want to be direct about something that often gets buried in the fine print: the EU AI Act explicitly acknowledges that demanding the same documentation burden from a 15-person startup as from a €50 billion corporation would be absurd. Article 11(2) gives SMEs the right to provide Annex IV documentation in a simplified manner, and notified bodies are legally required to accept that form for conformity assessment.[15]
SMEs here means enterprises with fewer than 250 employees and annual turnover not exceeding €50 million (or balance sheet under €43 million),[16] as defined in the EU SME definition framework. If you qualify, what does “simplified” actually mean in practice?
It means you can combine sections that large organizations separate. You can write shorter descriptions for elements with lower risk relevance to your specific system. You can lean more on references to existing internal processes rather than standalone documented procedures. You can use shorter test reports rather than full-scale validation studies.
What simplified documentation doesn’t mean: skipping the substantive requirements. An SME deploying a CV screening tool still has to demonstrate bias testing. A startup building a credit scoring model still needs a risk register. The simplification is in presentation and volume — not in the rigor of what gets demonstrated.
💡 A practical note for SMEs
The most defensible SME dossier is a short one that says something real about every section — not a long one that says nothing specific anywhere. A 25-page dossier where every section is substantively addressed beats an 80-page document padded with methodology descriptions and generic risk language. Regulators can tell the difference immediately.
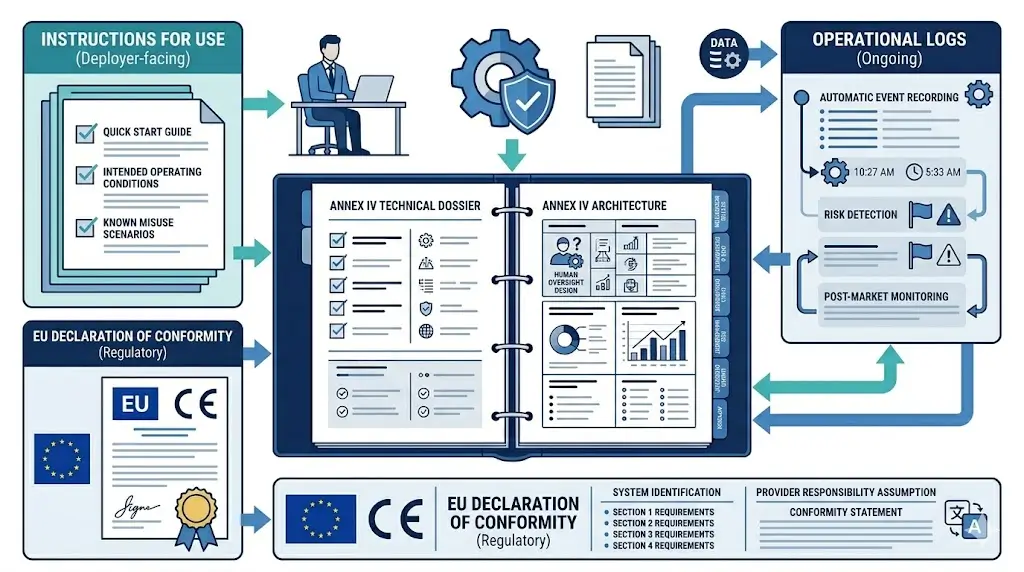
The Four Distinct Document Types
Four separate documentation artifacts are required for high-risk AI systems. Each one does a different job. Understanding that distinction prevents the most expensive documentation mistake: trying to make one document serve all four purposes.
| Document | Legal Basis | Primary Audience | Purpose | Who Prepares It |
|---|---|---|---|---|
| Annex IV Technical Dossier | Articles 11 & 18, Annex IV [2] | Regulators, notified bodies | Complete regulatory record of system design, training, testing, and governance | Provider |
| Instructions for Use | Article 13, Annex V [3] | Deployers | Operational guidance for safe, compliant deployment | Provider |
| Operational Logs | Articles 12 & 26 [4] | Internal compliance, regulators on request | Audit trail of system operation and human oversight actions | Provider (builds capability) + Deployer (runs it) |
| EU Declaration of Conformity | Article 47, Annex V [5] | Regulators, EU AI database | Formal legal attestation of compliance | Provider |
When Documentation Must Be Ready
Timing is one of the areas where good intentions most often collide with reality. The Annex IV dossier and Instructions for Use must be complete before your high-risk AI system hits the EU market. Not “mostly done.” Not “drafted and under review.” Complete. You can’t launch and backfill documentation later — that creates a compliance gap and significant legal risk if anything goes wrong during that window.
For systems already deployed before August 2, 2026, the transition period gives you until August 2, 2027 for Annex III systems.[6] But the moment you make a significant change to the system after August 2026, that grace period evaporates — the changed system must comply immediately.
Operational logs don’t get a grace period of any kind. Logging infrastructure must be live from the moment the system goes into operation.[4] Build and test it before deployment. Adding it afterward isn’t just risky — it means any incidents that occurred in the unlogged window are essentially unauditable.
🕑 Realistic timeline check
In practice, building a complete Annex IV dossier for a single high-risk AI system takes 6–12 weeks of dedicated effort from a cross-functional team. If you have multiple systems in scope, plan accordingly. Seriously — three weeks before launch is not enough time, regardless of how organized you are.
!
Digital Omnibus: What’s changing and what isn’t
In November 2025, the European Commission published the Digital Omnibus — a simplification package that proposes extending the Annex III compliance deadline from August 2, 2026 to as late as December 2, 2027 (a 16-month extension), with a backstop of August 2, 2028 for Annex I products.[7]
This extension is not yet law. As of March 2026, the Digital Omnibus is still in legislative transit. The August 2, 2026 deadline is legally binding until the EU Council and European Parliament formally adopt any changes.
My honest recommendation: don’t slow down or pause your documentation program based on a proposed extension that may not materialize on the timeline you’re hoping for. Organizations that achieve compliance before August 2026 gain competitive advantage regardless of what happens with the Omnibus. And enforcement of already-identified violations won’t be retroactively waived.
Last verified: March 2026. Monitor eur-lex.europa.eu for the Official Journal adoption notice.
Annex IV Deep Dive: All 10 Required Elements Explained
Annex IV identifies eight core legal content areas — but a complete, audit-ready dossier in practice covers ten structured sections, per European AI Office guidance, to ensure full traceability. For each one, I’ll tell you what the law actually says, what “good enough” looks like in practice (this part is usually missing from legal summaries), and the specific gap I see teams leave most often.
| Section | Legal Basis | Responsible Party | Update Frequency |
|---|---|---|---|
| 1. General System Description | Annex IV §1 | Provider | On any change to purpose or scope |
| 2. Design Specifications | Annex IV §2 | Provider (Engineering) | On architectural or methodology change |
| 3. Training & Test Data | Annex IV §3 | Provider (Data Science) | On retraining or dataset change |
| 4. Performance Metrics | Annex IV §4 | Provider (Engineering) | On retraining or new test cycle |
| 5. Risk Management | Annex IV §5, Article 9 | Provider (Legal/Compliance) | Continuous — quarterly review minimum |
| 6. Post-Market Changes | Annex IV §6 | Provider | On every material change — version log |
| 7. Standards & Conformity Assessment | Annex IV §7 | Provider (Legal) | When harmonized standards published; on re-assessment |
| 8. EU Declaration of Conformity | Article 47, Annex V | Provider (Legal signatory) | On substantial modification or new assessment |
| 9. Human Oversight Measures | Article 14, Annex IV §1(f) | Provider + Deployer | On workflow or system change |
| 10. Post-Market Monitoring Plan | Article 72, Annex IV §8 | Provider | Annually + on incident or performance alert |
Element 1: General System Description
Don’t mistake this for a marketing one-pager. The general description is a regulatory overview — it needs to tell an authority everything they’d want to know before reading the rest of the dossier. What does it do? Who uses it? What does it connect to?
What the Act requires: A general description of the AI system including its intended purpose, version information, and how it interacts with hardware and software it connects to. Components, modules, and interfaces must be covered.
What sufficient looks like: A 2–5 page narrative covering the system’s purpose in plain language, the decision it makes or influences, input data types it processes, its output, the deployment environment, and integrations with other systems. Include a simple architecture diagram showing data flows. Describe who uses it and in what context.
The gap I see most often: Teams write an accurate description for the primary deployment context and forget that any other intended deployment variations must be covered too. If your AI system can run in multiple sectors or contexts, all of them need to be in the description — not just the main one your sales team focuses on.
📄 Section 1 — Minimum Content Checklist
- System name, version number, release date
- Intended purpose — the specific task the AI performs
- Intended users — who deploys it and who’s affected by it
- Deployment contexts and operational conditions
- Input data types and sources
- Output types (prediction, recommendation, classification, decision, content)
- System architecture diagram with data flow annotations
- Hardware and software dependencies and integration points
- Geographic scope — which EU member states it’ll be deployed in
Element 2: Design Specifications and Development Process
This section is where you document how the system was built — and crucially, why the key choices were made. Regulators use this section to assess whether development followed accountable practices or was largely ad hoc.
What the Act requires: Design specifications including the general logic and algorithms used, key design choices with justifications, the development methodology, training methodology, what the system was optimized for, and any trade-offs made in the design process.
What sufficient looks like: Document the model architecture, the loss functions optimized during training, key hyperparameter choices and their rationale, and any significant design decisions made in response to fairness, accuracy, or performance constraints. Write it at a level of detail that an AI engineer unfamiliar with your specific system could understand how it was built.
The gap I see most often: Teams document the final system architecture and omit the rejected alternatives. Regulators specifically look for evidence that key choices were deliberate — not arbitrary. Why did you choose this approach over alternatives? Why did you make the trade-off you made? If you can’t answer those questions in writing, this section will feel thin to anyone reviewing it seriously.
Element 3: Training, Validation, and Testing Data
Of all the Annex IV sections, this one gets the most scrutiny from technical reviewers. And it’s the one most often incomplete. I don’t think that’s because teams are hiding anything — it’s because data documentation feels less formal than system documentation, and the teams that trained the model are often different from the teams building the compliance dossier.
What the Act requires: Documentation of all three datasets used in development: their provenance (where they came from and how they were collected), scope and characteristics, preprocessing procedures, data quality measures, and known limitations. You also need to address how the data accounts for the geographic, behavioral, and contextual settings of actual deployment.
What sufficient looks like: For each dataset — training, validation, and testing separately — document: the source, when it was collected, who collected it and how, what preprocessing and cleaning was applied, size and format, demographic and contextual characteristics represented, known coverage gaps or biases, and what steps were taken to address identified biases.
The gap I see most often: Training data gets thorough treatment; validation and test sets get three sentences each. All three require equal documentation depth. More importantly, teams rarely include the “representative coverage” analysis — the demonstration that data actually reflects the population the AI will encounter in deployment. This matters especially for systems affecting EU citizens across diverse demographics. A model trained on predominantly Northern European data that gets deployed pan-EU has a problem that needs to be documented and addressed, not quietly omitted.
📄 Section 3 — Data Documentation Template (repeat for each dataset)
- Dataset name and version: [identifier]
- Source and collection method: [origin, collection process, data provider]
- Collection date range: [from] to [to]
- Dataset size: [number of records, features, total size]
- Demographic coverage: [geographic, age, gender, language representation]
- Preprocessing steps applied: [cleaning, normalization, augmentation, anonymization]
- Known limitations or gaps: [underrepresented groups, historical bias sources]
- Bias assessment results: [methodology used, findings, mitigations applied]
- Data access and storage: [where stored, access controls, GDPR compliance status]
- Data retention policy: [how long retained, deletion schedule]
Element 4: Performance Metrics and Validation Results
This is the quantitative backbone of your dossier. If the rest of the document describes what you built and how, this section proves that it actually works — and is honest about where it doesn’t.
What the Act requires: The measures taken to test and validate the system, the metrics used to evaluate performance, results of those evaluations, how performance varies across demographic subgroups and deployment contexts, thresholds below which performance is unacceptable, and what happens when those thresholds are approached.
What sufficient looks like: Document your primary performance metrics — accuracy, precision, recall, F1, AUC-ROC, or domain-specific equivalents — with values on each test dataset. Break those metrics down by demographic subgroup: at minimum by gender, age group, and geographic region for any system deployed across the EU. Set the acceptable performance floor for each metric and specify what monitoring event triggers a re-evaluation.
The gap I see most often: Aggregate metrics look great; subgroup performance tells a different story that never makes it into the dossier. This is both a technical problem and a documentation problem. Regulators expect transparency about limitations — not perfection. A dossier that clearly identifies subgroup performance gaps and explains what was done about them is far more credible than one claiming flawless results across the board. Reviewers don’t trust perfect numbers. They trust honest ones.
Element 5: Risk Management Documentation
Here’s a misunderstanding that trips up a lot of teams: the risk management section isn’t just an output of your risk process — it’s documentation of the process itself. Regulators don’t just want to see your risk register. They want to see evidence that you ran a genuine risk management system, not that you filled in a template.
What the Act requires: A description of the risk management system applied to the AI system, including the risks identified, the evaluation methodology, mitigation measures applied, and the residual risks remaining after mitigation. This section links directly to the ongoing risk management system required under Article 9.[19]
What sufficient looks like: Include a risk register with each identified risk, its likelihood and severity ratings (with reasoning, not just numbers), the specific mitigation applied, and the post-mitigation residual risk. Document the methodology used — ISO 31000, NIST AI RMF, or your own internal framework, and explain why. Cover both technical risks (model failure modes, adversarial attacks, distributional shift) and sociotechnical risks (misuse scenarios, deployer over-reliance on AI outputs, context where the system shouldn’t be used but might be).
The gap I see most often: Technical risks get a thorough treatment. Sociotechnical risks — especially automation bias and out-of-scope deployment — get almost nothing. The Act specifically requires consideration of human-AI interaction risks.[8] A junior employee who relies on an AI recommendation without critical review because “the AI said so” is a real risk with real consequences. It belongs in your risk register.
Documentation in Practice: A Legal Tech Company’s Experience
Contract Review AI — Illustrative Case
A legal technology company deploying a contract risk assessment AI for law firms in Germany and France had put significant effort into their technical risk documentation — incorrect clause identification, missed risk flags, false negatives on specific contract types. Solid work, as far as it went.
What they hadn’t addressed at all was automation bias. Junior lawyers were accepting AI risk assessments without independent review — particularly when they were under deadline pressure and the AI output looked authoritative. That’s a textbook sociotechnical risk, and it wasn’t in the dossier anywhere.
After a compliance review in late 2025, they added two new entries to their risk register: over-reliance leading to missed legal issues, and inappropriate deployment in jurisdictions with limited training data coverage. They updated their Instructions for Use to require senior legal review of AI-flagged critical risks, and added minimum training requirements for deploying firms.
The dossier that came back from regulatory review with zero additional queries was the second version. The first was returned with a specific request for sociotechnical risk coverage.
📋 Halfway through the 10 elements — Elements 1–5 covered what you built and how you managed risk during development. Elements 6–10 cover how you govern, maintain, and demonstrate accountability for the system going forward.
Element 6: Post-Market Changes and Versioning
Your dossier isn’t done when it’s done. That’s the mindset shift that most teams struggle with — treating documentation as a project with a completion date rather than an ongoing governance practice.
What the Act requires: Documentation of changes made to the system after deployment, with particular attention to changes that constitute a “substantial modification.” A substantial modification is any change that affects the system’s compliance with the Act’s requirements — new intended purpose, significant performance changes, new risks introduced, architectural changes that alter how the system operates.
What sufficient looks like: Maintain a version log as a permanent appendix to your technical dossier. Each entry should document what changed, why, when, and whether it constitutes a substantial modification requiring a new conformity assessment. Each version log entry should link to the specific dossier sections it updates.
The gap I see most often: Documentation updates happen reactively — triggered by regulatory reviews or audits — rather than as a continuous process built into the development pipeline. The most effective fix is to make documentation impact assessment a mandatory gate in every model deployment approval process. Before the change goes live, someone signs off that the dossier has been updated to reflect it. Not after.
Element 7: Standards and Conformity Assessment Procedures
This section requires a bit of upfront honesty about the current state of the standards landscape — because the instinctive approach (list the applicable EU harmonized standards) isn’t currently possible, for a reason most articles on this topic don’t address.
The harmonized standards gap: As of March 2026, no EU harmonized standards for the EU AI Act have been formally published.[9] CEN and CENELEC are working on them — the first relevant standard, prEN 18286 on AI quality management systems, entered public enquiry in October 2025 — but publication of finalized harmonized standards is estimated for late 2026 at earliest.
This isn’t a technicality to worry about. The Act explicitly provides for exactly this situation under Article 40(2) and Annex IV:[10] where harmonized standards don’t exist, providers document compliance by describing in detail the solutions they adopted to meet the requirements of Chapter III, Section 2. You document your alternative approach. Problem solved — provided you do it properly.
What sufficient looks like right now: Start with a clear statement that no EU AI Act harmonized standards were available at the time of your conformity assessment. Then document the alternative standards you applied. The most widely used alternatives currently are: ISO/IEC 42001 (AI Management Systems), ISO/IEC 23894 (AI Risk Management), ISO/IEC 27001 (Information Security), ISO/IEC 23053 (AI Framework), and NIST AI Risk Management Framework 1.0 for international alignment.
For each standard, specify exactly which clauses apply to your system, how you addressed each clause, and what evidence demonstrates compliance. Vague references — just listing “ISO/IEC 42001” without clause-level mapping — are treated as no reference at all by regulatory reviewers. They’ve seen that shortcut before.
📄 Section 7 — Standards Documentation Template (Pre-Harmonized Standards)
Use this approach until EU AI Act harmonized standards are published. Update when they become available.
- Statement re: harmonized standards: “No EU harmonized standards for Regulation (EU) 2024/1689 were available at the date of this conformity assessment ([date]).”
- Alternative standards applied: List each with full title, edition, relevant clause numbers
- Clause-level mapping: For each clause, describe specific implementation and evidence
- Conformity assessment procedure: Annex VI internal control / Annex VII quality management system / third-party notified body
- Notified body details (if applicable): Name, EU identification number, certificate reference, date
- Planned update: “This section will be updated to reference applicable harmonized standards upon their publication, estimated [date].”
The gap I see most often: Leaving this section blank because teams couldn’t find applicable harmonized standards, then never going back to it. Or listing standard names without clause-level evidence — which is functionally the same as leaving it blank. Neither passes review.
Element 8: EU Declaration of Conformity
The Declaration of Conformity is both a documentation artifact and a legal commitment. It’s the formal document through which the provider attests that the high-risk AI system meets all applicable requirements of the Act. Don’t treat it as a checkbox in a compliance system. It’s a signed legal document — prepare it accordingly.
What the Act requires: Provider identity and contact information, system description (name, version, intended purpose), an explicit statement of conformity referencing Regulation (EU) 2024/1689, references to harmonized standards applied (or alternative approaches), date, and signature of an authorized representative.
What sufficient looks like: Prepare this with or under close review by legal counsel. Sign it at the right organizational level. Attach it to the technical dossier and include it in EU AI database registration where required. Template structures are available from the European AI Office — use them as a starting point, not as a substitute for legal review.
✓ Declaration of Conformity — Required Elements
- Provider name, registered address, EU authorized representative (if non-EU provider)
- Full system name, version, and unique identifier
- Intended purpose as documented in the technical dossier
- Explicit conformity statement: “This AI system is in conformity with Regulation (EU) 2024/1689…”
- References to harmonized standards or alternative specifications applied
- Notified body name and certificate number (where third-party assessment was required)
- Place, date, and version of the Declaration
- Name, title, and signature of the authorized signatory
Element 9: Human Oversight Measures Documentation
Human oversight is addressed throughout the Act — primarily Article 14[17] — and the documentation of it touches several Annex IV sections. But it deserves its own treatment here because teams consistently underdo it, and the gap is usually the same: they document oversight as an organizational procedure without documenting the technical features that make that procedure possible.
What the Act requires: Documentation of the human oversight measures built into the AI system — specifically how the system enables natural persons to understand and monitor its operation, how humans can intervene and override outputs, and what design measures ensure that humans can choose not to use the system’s output in specific situations.
What sufficient looks like: Document the actual technical features, not the policy intention. The specific interface elements or API capabilities through which an operator can review outputs before they’re acted on. The override mechanism and how it’s triggered. Confidence score or uncertainty indicators visible to operators. Automatic holds that trigger human review when the system encounters low-confidence or out-of-distribution inputs. Include a process diagram showing where AI output flows to decision-makers and where the override points are.
The gap I see most often: “A manager reviews all decisions” is not documentation of human oversight. It’s a description of organizational intent. The Act requires the system to support oversight technically — not just the organization to intend it. If your system doesn’t expose uncertainty scores, has no override mechanism, and doesn’t log operator review actions, the oversight documentation will be incomplete regardless of what your process documents say.
Element 10: Post-Market Monitoring Plan (Article 72)
Honest observation: this is the section most often written at the last minute, in the least detail, with the most generic language. Which is ironic, because it’s one of the sections regulators use most to assess whether a provider is genuinely committed to ongoing compliance or just trying to get through the door.
Article 72 requires providers to establish and document a post-market monitoring system that proactively collects and reviews data on system performance throughout its operational lifetime.[11] The monitoring plan must specify how the provider will detect performance degradation, identify new or emerging risks, track incidents reported by deployers, and determine when corrective action or a new conformity assessment is needed.
What sufficient looks like: Five components, each documented with real specificity. First, the monitoring metrics — what performance indicators are tracked post-deployment, at what frequency, against what thresholds. Second, the data collection mechanism — how operational data flows from deployer environments back to you for analysis, and what deployer cooperation that requires. Third, the incident intake process — how deployers report anomalous behavior, who receives those reports, and within what timeframe you investigate and respond. Fourth, the serious incident reporting procedure — the escalation path for incidents that must be reported to national market surveillance authorities. Under Article 73, the legal reporting timelines are clear: 15 days for any serious incident from the moment the provider becomes aware of a causal link; 10 days if the incident may have resulted in a person’s death; and 2 days for incidents involving widespread infringement or serious disruption of critical infrastructure.[12] Fifth, the periodic review cadence — at minimum annual reviews, with a documented decision process for when a review triggers a documentation update, corrective action, or a full new conformity assessment.
The gap I see most often: Plans that say “we will monitor performance quarterly” without specifying what data is collected, how, from whom, by which team member, and what action threshold triggers a response. That’s not a monitoring plan. It’s a statement of intention. A monitoring plan reads like an operational procedure — with owners, timelines, data sources, and decision criteria at every step.
Instructions for Use: The Deployer-Facing Document
The Instructions for Use (IFU) is not a section of your technical dossier. It’s a completely separate mandatory document that you supply to every deployer alongside the system. The dossier is for regulators. The IFU is for the people actually running your system — and it needs to be written for them, not for a compliance reviewer.
What Instructions for Use Must Contain
Article 13 specifies minimum IFU content.[3] Each element has to be written in plain, actionable language. A deployer who isn’t an AI engineer needs to be able to read this and understand what they’re supposed to do.
At minimum, the IFU must cover: the provider’s identity and a compliance contact point; the system’s intended purpose — specific tasks, specific contexts, no vague generalities; performance characteristics including accuracy metrics, error rates, and — this part is critical — how accuracy varies across different demographic groups, geographic regions, and operational conditions.
It also needs to cover: known risks and limitations, including conditions where incorrect outputs are more likely, and contexts where the system simply shouldn’t be used; human oversight guidance — specific steps deployers must take, who should review AI outputs, and when AI outputs must not be used without independent verification; technical infrastructure requirements for deployment to work as validated; relevant cybersecurity measures deployers should implement; and how to report incidents or anomalous behavior back to you.
Instructions for Use — Minimum Section Structure
Use this as a starting template. Adapt the depth of each section to your system’s risk level and deployment context.
1. Provider Information
- Provider name, registered address, and EU authorized representative (if non-EU)
- Compliance contact point — name, email, response SLA for compliance queries
- System name, version, and unique identifier matching the technical dossier
2. Intended Purpose and Scope
- The specific task or decision the AI is designed to support
- Authorized deployment contexts (sectors, user roles, geographic scope)
- Explicit list of out-of-scope uses — contexts where the system must NOT be deployed
3. Performance Characteristics and Known Limitations
- Overall accuracy metrics on validated test sets (with test set description)
- Performance breakdown by demographic subgroup, language, and geographic region
- Known failure modes — specific conditions where accuracy drops significantly
- Error rate ranges under normal operating conditions
- Performance degradation indicators to watch for in live operation
4. Human Oversight Requirements
- Minimum qualifications for human reviewers of AI outputs
- Mandatory review steps before AI outputs are acted upon
- Circumstances where AI output must NEVER be acted on without independent verification
- Override procedure — how to record a human decision that overrides AI output
- Escalation path for high-stakes or unusual outputs
5. Technical Infrastructure Requirements
- Minimum hardware and software requirements for validated performance
- Integration prerequisites and dependencies
- Data input specifications — format, quality, and preprocessing requirements
- Logging configuration — confirming logging is activated and specifying storage location
6. Security and Incident Reporting
- Cybersecurity measures deployers must implement in their environment
- Definition of what constitutes an “incident” or anomalous behavior for this system
- Provider incident reporting channel and expected response time
- Deployer’s obligation to report serious incidents to National Competent Authority
7. Deployer Obligations Summary
- Checklist of deployer documentation obligations (deployment context assessment, oversight records, logs)
- FRIA obligation — whether deployer must conduct a Fundamental Rights Impact Assessment
- Reference to provider’s EU AI database registration entry
How It Differs from the Annex IV Dossier
The distinction matters more than teams usually realize. The Annex IV dossier contains proprietary design information, training data details, and testing methodologies that you legitimately don’t want circulating freely among every organization that licenses your system. The IFU contains none of that — only the operational information deployers need to use the system responsibly.
Never hand a deployer your Annex IV dossier as a substitute for an IFU. You either expose proprietary technical information you didn’t intend to share, or — more commonly — the deployer receives a document so technical they can’t actually act on it. Both create compliance problems. One additional problem: if a deployer can’t operationalize their oversight obligations because your IFU is inadequate, you share responsibility for whatever goes wrong downstream.
Record-Keeping and Automatic Logging Requirements
Logging is the documentation requirement that most engineering teams initially underestimate. The surface-level description sounds simple — generate logs of what the system does. In practice, the requirements for what those logs must contain, how they must be stored, and who’s responsible for what, are more nuanced than most teams plan for.
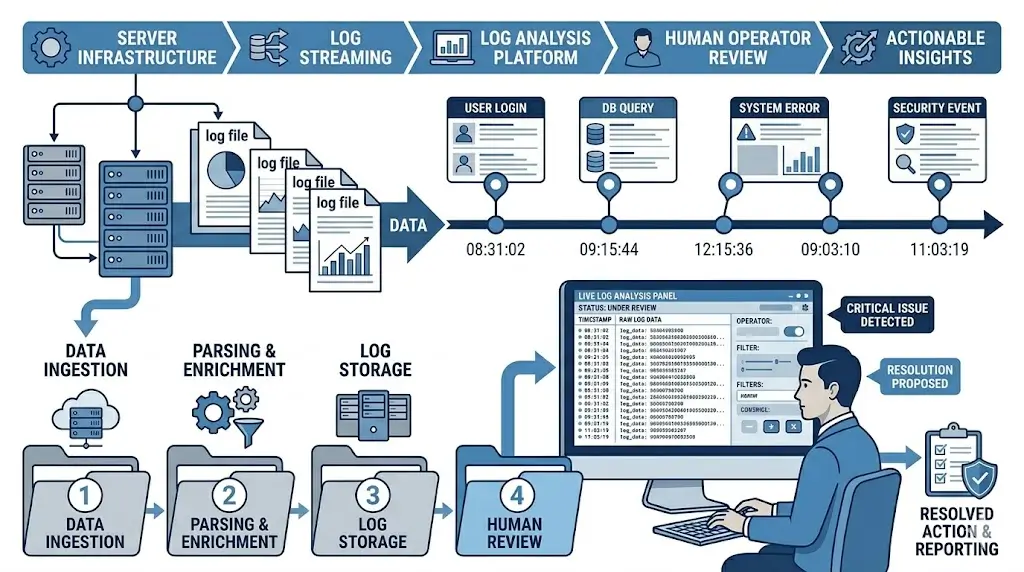
What Your Logs Must Capture
Article 12 specifies the minimum content. For each operational instance of the AI system, you need to capture four things:
Operational period: The start and end time of each instance — each time the system processes an input and produces an output. Every single one, timestamped.
Input identifier: A reference to the specific input data processed. This can be the input itself, a cryptographic hash, or a secure identifier that links back to the source data. The key word here is “retrievable” — the log entry must allow you to reconstruct what the system actually processed, not just when it ran.
Output generated: The actual decision, prediction, recommendation, or classification produced. Not a summary. Not a category of output. The actual output, captured as generated.
Human verification record: Where a human operator reviews or verifies the AI output before action is taken, the log must capture who that person was and what the outcome of their review was. This is the mechanism through which human oversight becomes auditable — and without it, you have no way to demonstrate that oversight actually happened, even if it did.
Retention Periods and Storage Requirements
The 10-year minimum retention requirement is one of the parts that surprises organizations most. Ten years from market placement — or from the most recent significant change, whichever is later — for both the technical dossier and operational logs.[13] That clock doesn’t restart just because you decommission the system.
| Scenario | Minimum Retention | Clock Starts From |
|---|---|---|
| Standard high-risk AI system | 10 years | Date of market placement or first deployment |
| System with significant post-launch modification | 10 years | Date of most recent significant change |
| System decommissioned before 10 years | 10 years | Date of original market placement (decommissioning does not shorten the clock) |
| Medical device AI (MDR overlap) | 15 years or longer | Per MDR Article 10[14] — sector law governs where stricter |
| Financial services AI (DORA overlap) | 5–10 years (varies) | Per applicable EBA guidelines and DORA Article 12[20] — assess individually |
| Employment / HR AI | 10 years minimum | Plus any national employment law retention requirements |
On storage format: the Act doesn’t mandate a specific technical approach. What it requires is integrity and accessibility. Logs must be stored in a way that prevents unauthorized modification — immutable or append-only storage with cryptographic integrity verification is the right technical solution here. The Act does not specify an exact response window for providing logs to authorities on request,[13] but legal counsel consistently recommends treating any regulatory log request as requiring same-week response capacity at minimum, with 24–48 hour capability for requests flagged as urgent by the authority.
Deployer Log Obligations vs. Provider Log Obligations
The responsibility split here is cleaner than it might initially appear. Providers build systems capable of generating compliant logs. Deployers ensure logging is actually running and maintained in their specific environment.
Put differently: if you’re a provider and your system has no logging capability built in, you’ve violated the Act — regardless of whether the deployer wanted to enable logging or not. If you’re a deployer and you’ve disabled or bypassed logging functionality, that’s your violation, regardless of how compliant the provider’s system is.
This responsibility split should be explicit in provider-deployer contracts: which party stores the logs, who controls access, who produces log extracts in response to regulatory requests, and what happens to logs when the deployment relationship ends.
Documentation as a Living System: Maintenance and Version Control
The single most important mindset shift for anyone building a documentation program: there is no finish line. Documentation isn’t a deliverable you complete before launch and file away. It’s a governance practice with the same operational permanence as the AI system itself. A technical dossier that was accurate at launch but reflects a system you’ve since updated isn’t just outdated — it’s non-compliant.
When You Must Update Documentation
Certain changes trigger mandatory updates. Others require a review even if the documentation might not change. Know the difference.
Mandatory update triggers: any retraining on new or significantly expanded data; architectural changes; changes to intended purpose or deployment context; performance degradation below documented thresholds identified through monitoring; new risks identified through post-market surveillance; changes to hardware or software infrastructure affecting system behavior; regulatory guidance updates from the European AI Office that affect compliance interpretation for your system type.
Review triggers (update if affected): annual scheduled review; any significant incident reported by a deployer; market expansion into new EU member states; changes in the demographic composition of your user base.
Version Control and Change Management
Each version of the technical dossier must be distinguishable from prior versions, with a clear record of what changed, when, and why. This isn’t just good practice. If an incident occurs, regulators will want to reconstruct the state of your documentation at the time — which requires version management that actually preserves history, not just a current-state document that gets overwritten.
Maintain a version log as a permanent appendix. Each entry: version number, date, sections modified, brief description of what changed and why, name of the person who made the change, name of the person who approved it. This log must be immutable once created — entries can’t be edited or deleted retroactively. For substantial modifications that trigger a new conformity assessment, treat the new version as a distinct document and archive the prior version rather than overwriting it.
Recommended Tooling for Documentation Management
The tooling choice matters more than it might seem. The right tool makes it possible to maintain documentation sustainably over the system’s operational life. The wrong tool creates a fragile process that gets abandoned six months after launch.
GRC platforms like OneTrust, ServiceNow GRC, or LogicGate work well for organizations with multiple high-risk systems running parallel documentation programs. They allow teams to structure compliance documentation within a framework, link evidence artifacts to specific requirements, track gap remediation, and generate audit-ready reports.
Document management systems with version control: Confluence, SharePoint with compliance modules, or Notion with structured databases can work for smaller programs. Non-negotiable requirements: version history that can’t be edited retroactively, access controls distinguishing view vs. edit permissions, and export capability for regulatory submission.
ML model documentation tools: Model cards (Google’s Model Card Toolkit), model registries in MLflow or Weights & Biases, and specialized AI governance platforms like Credo AI or Truera can generate technical documentation directly from training artifacts. These significantly reduce manual effort on Sections 2–4 and are worth evaluating if you’re building a documentation program from scratch.
Whatever you choose: documentation tooling must integrate with your AI development and deployment pipeline. Not as a separate manual process. Every model deployment should trigger a documentation review gate before it’s approved.
Annex IV Documentation Template: A Practical Starting Structure
The following template gives you a complete structure for an Annex IV technical dossier. Adapt it to your system — this is a starting point, not a mandated format. Regulators don’t require a specific document template, but they do require that every Annex IV element gets addressed. This structure ensures none get missed.
Complete Template Structure with Section Headers
ANNEX IV TECHNICAL DOSSIER
EU AI Act — Article 11 and Annex IV Compliant
Document Control
- System Name and Version: [____]
- Document Version: [____] | Date: [____]
- Prepared by: [____] | Approved by: [____]
- Next Scheduled Review: [____]
SECTION 1 — General Description of the AI System
- 1.1 System overview and intended purpose
- 1.2 Intended users and affected persons
- 1.3 Deployment contexts and geographic scope
- 1.4 System architecture diagram and data flow
- 1.5 Hardware and software dependencies
- 1.6 Integration points with other systems
- 1.7 High-risk classification basis (Annex I / Annex III)
SECTION 2 — Design Specifications and Development Process
- 2.1 Model architecture and algorithmic approach
- 2.2 Development methodology and key design decisions
- 2.3 Optimization objectives and trade-offs made
- 2.4 Rejected design alternatives and reasoning
- 2.5 Key design choices affecting fairness, accuracy, or transparency
SECTION 3 — Training, Validation, and Testing Data
- 3.1 Training dataset: provenance, scope, preprocessing, bias assessment
- 3.2 Validation dataset: provenance, scope, preprocessing, representativeness
- 3.3 Test dataset: provenance, scope, independence from training data
- 3.4 Demographic and contextual coverage analysis
- 3.5 Known data limitations and mitigation measures
- 3.6 Data governance and GDPR compliance status
SECTION 4 — Performance Metrics and Validation Results
- 4.1 Primary performance metrics and results (aggregate)
- 4.2 Disaggregated performance by demographic subgroup
- 4.3 Performance by geographic region and deployment context
- 4.4 Acceptable performance thresholds and basis for threshold selection
- 4.5 Robustness and adversarial testing results
- 4.6 Known accuracy limitations and documented failure modes
SECTION 5 — Risk Management Documentation
- 5.1 Risk management methodology and framework applied
- 5.2 Risk register: identified risks, likelihood, severity, mitigation, residual risk
- 5.3 Technical risk coverage: failure modes, adversarial attacks, distributional shift
- 5.4 Sociotechnical risk coverage: misuse, over-reliance, inappropriate deployment contexts
- 5.5 Vulnerable population risk assessment
- 5.6 Post-market risk monitoring procedures
SECTION 6 — Human Oversight Measures
- 6.1 Human oversight design — how oversight is built into the system technically
- 6.2 Override and intervention capabilities
- 6.3 Uncertainty and confidence indicators visible to operators
- 6.4 Deployer-level oversight requirements
- 6.5 Training requirements for human overseers
SECTION 7 — Logging and Monitoring Specifications
- 7.1 Logging architecture and technical implementation
- 7.2 Log content specification (what is captured per operational instance)
- 7.3 Log retention configuration and storage security
- 7.4 Monitoring triggers and escalation procedures
SECTION 8 — Cybersecurity Measures
- 8.1 Cybersecurity risk assessment specific to AI system
- 8.2 Protections against data poisoning, model evasion, model extraction
- 8.3 Access controls and authentication measures
- 8.4 Security testing results
SECTION 9 — Standards Applied and Conformity Assessment
- 9.1 Statement regarding harmonized standards availability (see Element 7 guidance)
- 9.2 Alternative standards applied with clause-level mapping
- 9.3 Conformity assessment procedure followed (Annex VI or VII)
- 9.4 Notified body reference and certificate number (where applicable)
- 9.5 EU Declaration of Conformity (attached)
SECTION 10 — Post-Market Monitoring and Version History
- 10.1 Post-market monitoring plan (Article 72): metrics, data collection, incident intake, serious incident reporting, review cadence
- 10.2 Version log: all changes since initial market placement
- 10.3 Significant modification assessment log
APPENDICES
- A — Instructions for Use (deployer-facing document)
- B — EU Declaration of Conformity (signed)
- C — Test reports and validation evidence
- D — Bias assessment reports
- E — Third-party audit reports (where applicable)
What “Sufficient” Looks Like: Regulator Expectations
The Act sets requirements but doesn’t specify minimum page counts or document formats. What regulatory reviewers actually look for comes from analogous regulatory frameworks — medical devices, financial services — where similar documentation culture has developed over years.
Three principles consistently distinguish documentation that passes review from documentation that doesn’t.
First, specificity beats volume. A five-page section that specifically addresses every required element with concrete data is worth more than thirty pages of generic methodology descriptions. Reviewers can tell immediately when documentation was written for the system in front of them versus assembled from a generic template.
Second, honesty about limitations builds credibility. A dossier claiming perfect performance and zero risks signals either that the team didn’t look hard enough, or that they found problems and chose not to document them. Neither is a good sign. Clearly documenting known subgroup performance gaps and what was done about them — clearly documenting risks that couldn’t be fully mitigated and why they were accepted — demonstrates the kind of rigorous self-assessment the Act is designed to produce.
Third, claims need evidence trails. Everything asserted in the documentation should be traceable to underlying evidence — test reports, bias assessment outputs, training data logs. A dossier making assertions without supporting evidence is insufficient regardless of how comprehensive it looks on the surface.
The 8 Most Common Documentation Mistakes (and How to Avoid Them)
These are the documentation gaps that consistently create the most regulatory risk — not in my opinion, but based on the patterns that show up repeatedly in pre-compliance reviews.

Mistake 1: Treating documentation as a one-time deliverable. Documentation is a living system. Teams that complete the dossier at launch and never update it will find that regulatory authorities can identify discrepancies between documented and actual system behavior — particularly after model updates. Build documentation review into every release process.
Mistake 2: Using the Annex IV dossier as the Instructions for Use. The technical dossier is a regulatory record. The Instructions for Use is an operational guide for deployers. Conflating them results in deployers receiving documents that are either too technical to act on or that expose provider proprietary information unnecessarily.
Mistake 3: Documenting only aggregate performance metrics. The Act explicitly requires disaggregated performance data across demographic subgroups. A dossier reporting overall accuracy without demographic breakdown will fail regulatory review. Run and document subgroup analysis before finalizing this section.
Mistake 4: Vague risk register entries. “Risk of inaccurate output” is not a risk entry. A real entry specifies the failure mode, the conditions under which it occurs, the likelihood and severity ratings with reasoning, the specific mitigation applied, and the residual risk level after mitigation. Generic risk registers signal that the risk assessment wasn’t genuinely conducted.
Mistake 5: Missing sociotechnical risks. Technical teams default to technical failure modes. The Act requires documentation of human-AI interaction risks too — over-reliance, misuse in out-of-scope contexts, inadequate oversight. These are often where real-world harm originates, and their absence from documentation is a significant red flag to reviewers.
Mistake 6: Claiming standard compliance without clause-level evidence. Writing “compliant with ISO/IEC 42001” without specifying which clauses apply, how they were addressed, and what evidence supports that claim is insufficient. Map each relevant standard clause to a specific action and a specific supporting document. A standard name with no implementation evidence is treated as no reference at all.
Mistake 7: No version control for the dossier itself. When an incident occurs, regulators want to know the state of your documentation at the time — not just today. Without proper version control and immutable version logs, you can’t demonstrate that. Implement version management from day one.
Mistake 8: Not documenting deployment context boundaries. Your system was trained and tested in specific conditions. If deployers use it outside those conditions — different demographics, different languages, different decision contexts — your documented performance metrics no longer apply. The dossier must explicitly state the scope of validated deployment conditions and flag that use outside those conditions requires additional assessment before deployment.
Documentation Obligations for Deployers
Here’s a misconception that catches deployers off guard: receiving a compliant AI system from a compliant provider does not mean your documentation obligations are satisfied. Deployers carry their own independent documentation requirements under the Act — obligations that exist regardless of provider compliance status.
What Deployers Must Document Independently
There are five categories of documentation deployers must maintain independently of the provider’s Annex IV dossier.
First, a deployment context assessment — a record that you evaluated whether the AI system is appropriate for your specific use case and whether your deployment context matches the intended purpose the provider documented. Must be done before deployment; must be updated when context changes.
Second, a human oversight implementation record — how you’ve actually implemented the oversight measures required by the provider’s Instructions for Use. Specific workflows. Specific qualifications for reviewers. Specific escalation paths. Operational, not theoretical.
Third, operational logs — while providers build the logging capability, you’re responsible for activating it, storing the logs, making them available to regulators when requested. Who stores them, who has access, how long you keep them, how you respond to regulatory requests — all of this needs to be documented.
Fourth, incident monitoring and reporting procedures — how you identify unexpected behavior, who investigates, when you escalate to the provider, and when you report to the relevant National Competent Authority.
Fifth — and this is the one deployers most frequently miss — Fundamental Rights Impact Assessments, for those categories of deployers where it’s required.
Fundamental Rights Impact Assessment (FRIA): When and How
The FRIA obligation under Article 27[18] is one of the most significant deployer-specific documentation requirements, and one of the most overlooked. If you fall into the categories below, this is mandatory — not optional best practice.
Who must conduct a FRIA: Two categories. First, bodies governed by public law — public authorities, publicly owned or publicly funded entities. Second, private bodies providing public interest services — banks and insurance companies, water/gas/heating service providers, transport operators, electronic communications networks, and organizations providing social protection, social security, or employment services.
Purely private commercial deployers outside these categories aren’t currently required to conduct FRIAs. But this may evolve, and many organizations in the grey zone choose to conduct them voluntarily as a governance measure.
What a FRIA must contain: A description of the deployment process; time period and geographic scope; categories of individuals and groups likely to be affected; specific fundamental rights at risk of being affected; severity and likelihood of each identified impact; measures taken to mitigate identified risks; and the internal governance process through which the assessment was conducted and reviewed.
Timing: Before the system goes live. Registered in the EU AI database where required. Updated when deployment context, affected populations, or risk profile changes materially.
| Deployer Type | FRIA Required? | EU AI Database Registration Required? |
|---|---|---|
| Government / public authority | Yes — mandatory | Yes |
| Public utility (water, energy, transport) | Yes — mandatory | Yes |
| Private bank or regulated financial services | Yes — mandatory | Yes |
| Private employer using internal HR AI | Not currently required | No (provider registers the system) |
| Private hospital or healthcare provider | Depends — assess whether publicly funded or governed | Depends on system type |
| Private EdTech deploying to public schools | Depends — assess deployment context and funding structure | Depends on system type |
Where Provider Documentation Ends and Deployer Begins
The table below maps each documentation artifact to its responsible party and shows where responsibilities overlap — which is more places than most teams initially assume.
| Documentation Element | Provider | Deployer | Shared |
|---|---|---|---|
| Annex IV technical dossier (Sections 1–10) | Primary obligation | Only if substantially modifying | — |
| Instructions for Use | Must prepare and supply | Must receive and implement | — |
| EU Declaration of Conformity | Must sign and register | — | — |
| Logging infrastructure (technical capability) | Must build into system | Must activate and maintain | — |
| Operational logs (storage and retention) | — | Responsible for deployment logs | Both retain for 10 years |
| Deployment context assessment | — | Must assess own use-case fit | — |
| Human oversight implementation record | Designs the capability | Documents its implementation | — |
| FRIA | — | Public bodies and regulated services only | — |
| Incident reporting to NCA | Serious incidents from own monitoring | Incidents identified in deployment | Both may have obligations |
| Post-market monitoring data | Owns the monitoring plan | Provides operational data to provider | Shared data flow required |
One final practical point: if your provider hasn’t given you adequate Instructions for Use, formally request them in writing and keep a record of that request. If something goes wrong, you want to be able to demonstrate that any documentation gap originated with the provider — not with your deployment practices.
Frequently Asked Questions: EU AI Act Documentation
These come up constantly in documentation workshops and compliance reviews. I’ve answered each one as directly as possible.
What documentation is required for high-risk AI systems under the EU AI Act?
Four separate artifacts — and they’re all mandatory. The Annex IV technical dossier is the comprehensive regulatory record covering design, training data, performance testing, risk management, and conformity assessment. Instructions for Use is the operational guide you supply to deployers. Operational logs are automatically generated records of system behavior that must be retained throughout the system’s operational life. The EU Declaration of Conformity is the formal legal attestation of compliance, signed by the provider before market placement.
All four must exist before the system is placed on the EU market or put into service. For systems already deployed, the August 2, 2027 transition deadline applies — but that grace period disappears the moment you make a significant change after August 2026.
How long must EU AI Act technical documentation be retained?
At least 10 years from market placement or the most recent significant change — whichever is later.[13] Both the Annex IV dossier and operational logs. Where sector regulations require longer periods (15 years for medical devices under MDR Article 10[14]), the longer requirement governs.
The clock doesn’t reset when you decommission the system. That surprises people. See the retention periods table in Section 4 of this guide for a breakdown by scenario. One note: the proposed Digital Omnibus may shift the compliance deadline for Annex III systems, but it doesn’t change Article 18 retention periods — those are separate provisions entirely.
Who is responsible for preparing Annex IV technical documentation?
Primarily the provider — whoever develops, trains, or places the system on the EU market. Deployers carry their own documentation obligations for their deployment context, but the core Annex IV dossier is a provider responsibility.
The exception: if a deployer substantially modifies the system — significantly changing its intended purpose, retraining it, integrating it in ways that alter core behavior — they cross into provider territory for the modified version. At that point, they need to prepare or update the full Annex IV documentation for what they’ve created.
Does the EU AI Act require documentation to be in a specific language?
No single mandatory language for the technical dossier. National market surveillance authorities may require documentation in their national language for systems deployed in their territory. In practice, most compliance teams work in English and maintain translations for major markets — German, French, Spanish, Italian — available on request.
The Instructions for Use is a different matter. It needs to be in a language the deployer can actually understand and act on. A German-language hospital deploying your AI needs German-language Instructions for Use. Plan accordingly when you’re building your documentation program for pan-European markets.
Can AI documentation be stored digitally?
Yes — and that’s the norm. The Act doesn’t require physical documentation. Digital storage with proper version control, access management, and audit trails is fully compliant — and far easier to maintain at the standard the Act requires over a 10-year retention period.
Specifically, your storage system should maintain version history that can’t be retroactively edited, distinguish between read and edit permissions, generate audit logs of access and modification, and export documentation in standard formats for regulatory submission. Those are the functional requirements, not specific technical products.
What’s the difference between technical documentation and instructions for use?
Different audiences, different purposes — and you can’t substitute one for the other. The technical dossier is a comprehensive regulatory record for authorities and notified bodies — detailed, technical, and containing proprietary information about your system that you legitimately protect. Instructions for Use is an operational guide for deployers — accessible language, operational focus, no proprietary technical detail.
Both are mandatory. Neither is optional because you have the other. The most common version of this mistake is handing deployers a summary of the technical dossier and calling it Instructions for Use. That fails both documents’ purposes simultaneously.
Next Steps: Building Your Documentation Program
If You’re Starting from Zero
Resist the urge to start writing documentation immediately. Start with a scoping exercise. Identify every high-risk AI system in scope. Then check what already exists from your engineering and data science teams — model cards, data dictionaries, test reports, architecture documents. In most organizations, significant portions of Sections 2, 3, and 4 exist in some form already. The work is formalizing and consolidating them, not building from scratch.
Assign ownership before writing starts: a technical writer or compliance specialist owns the dossier structure; an AI engineer owns Sections 2–4; legal or compliance owns Sections 5, 9, and the Declaration. Run a documentation sprint — 4–8 weeks for a single system with dedicated resources is realistic. Trying to document multiple systems in parallel with the same team usually means none of them get done well.
If You Have Existing Documentation That Needs Updating
Run the template structure from Section 6 against your existing documentation as a gap analysis. For each section: complete, partially complete, or missing. Prioritize gaps in Sections 3 (data documentation and bias assessment), 5 (sociotechnical risks), 7 (standards — especially given the harmonized standards situation), and the Declaration of Conformity. These are consistently the most incomplete sections.
Then assess whether your documentation is structured as a living system or as a point-in-time document. A well-maintained incomplete document is legally safer than a complete document with no update mechanism. Fix the process first, then the content gaps.
Your Documentation Program Readiness Checklist
✓ Documentation Program Readiness Checklist
- All high-risk AI systems identified and documentation scope defined
- Documentation ownership assigned across Legal, Engineering, and Compliance
- Document management tooling selected with version control and access management
- Annex IV template structure adapted for each system in scope
- Section 3 data documentation and bias assessment completed for all datasets
- Section 5 risk register includes both technical and sociotechnical risks
- Performance metrics documented at aggregate and subgroup level (Section 4)
- Instructions for Use prepared as a separate deployer-facing document
- Section 7 standards documentation completed using pre-harmonized approach
- Logging infrastructure built, tested, and producing compliant log output
- Log retention configuration meets 10-year minimum
- EU Declaration of Conformity drafted and awaiting legal sign-off
- FRIA completed and registered where required (public bodies and regulated services)
- Documentation update triggers integrated into the AI deployment pipeline
- Annual documentation review scheduled in compliance calendar
For the complete picture — risk management systems, human oversight measures, conformity assessment, and the full 90-day action plan — return to the EU AI Act Compliance Pillar Guide.
Next in this cluster series: EU AI Act vs. US AI Policy in 2026: Key Differences Businesses Operating in Both Markets Must Understand — a comparative analysis for multinational teams navigating divergent regulatory frameworks simultaneously.
Also directly connected to your documentation work: once your Annex IV dossier is underway, certain deployers must also conduct a Fundamental Rights Impact Assessment (FRIA) — a separate deployer obligation under Article 27 that works alongside your technical documentation. If you’re concerned about undocumented AI systems running in your organization, see our Shadow AI compliance guide. For US-market documentation obligations that differ from Annex IV, see our Colorado AI Act compliance guide.
📚 References and Legal Sources
- EU AI Act, Article 99(4) — Penalties for non-compliance with high-risk AI requirements: fines up to €15,000,000 or 3% of total worldwide annual turnover. Regulation (EU) 2024/1689 of the European Parliament and of the Council, Official Journal of the European Union, L 2024/1689, 12 July 2024. eur-lex.europa.eu
- EU AI Act, Articles 11 and 18 — Technical documentation obligation (Article 11) and retention requirement (Article 18). Regulation (EU) 2024/1689. eur-lex.europa.eu
- EU AI Act, Article 13 — Transparency and provision of information to deployers; minimum content for instructions for use. Regulation (EU) 2024/1689. eur-lex.europa.eu
- EU AI Act, Articles 12 and 26 — Record-keeping and automatic logging by providers (Article 12); obligations of deployers including log retention (Article 26). Regulation (EU) 2024/1689. eur-lex.europa.eu
- EU AI Act, Article 47 and Annex V — EU declaration of conformity: required content and legal effect. Regulation (EU) 2024/1689. eur-lex.europa.eu
- EU AI Act, Article 111(3) — Transitional provisions: high-risk AI systems (Annex III) already placed on market before August 2026 have until August 2, 2027 to comply, unless substantially modified. Regulation (EU) 2024/1689. eur-lex.europa.eu
- European Commission, Digital Omnibus Simplification Package — COM(2025) proposal to extend Annex III deadline to December 2, 2027 and Annex I deadline to August 2, 2028 (proposed, not yet adopted as of March 2026). European Commission, November 2025. Monitor: eur-lex.europa.eu for official adoption notice.
- EU AI Act, Article 9(2)(b) — Risk management scope includes risks arising from reasonably foreseeable misuse, as well as risks to vulnerable groups. Sociotechnical risks are within the mandatory risk management perimeter. Regulation (EU) 2024/1689. eur-lex.europa.eu
- CEN/CENELEC Standardization Mandate M/614 — European standardization mandate for EU AI Act; prEN 18286 (AI quality management systems) entered public enquiry October 2025. No EU harmonized standards formally published under the AI Act as of March 2026. cencenelec.eu
- EU AI Act, Article 40(2) — Where harmonized standards have not been published or do not cover all applicable requirements, providers may apply common specifications or must document alternative technical solutions demonstrating compliance with Chapter III, Section 2 requirements. Regulation (EU) 2024/1689. eur-lex.europa.eu
- EU AI Act, Article 72 — Post-market monitoring: providers must establish a post-market monitoring system proportionate to the AI system’s risk; the monitoring plan forms part of the technical documentation. Regulation (EU) 2024/1689. eur-lex.europa.eu
- EU AI Act, Article 73(2) and (4) — Serious incident reporting timelines: providers must notify national market surveillance authorities within 15 days of becoming aware of a causal link to a serious incident; within 10 days if the incident may have caused a person’s death; within 2 days for widespread infringement or serious disruption to critical infrastructure. An initial incomplete report is permissible under Article 73(5). Regulation (EU) 2024/1689. eur-lex.europa.eu
- EU AI Act, Article 18(1) — Technical documentation retention: providers must keep documentation available to national competent authorities for 10 years after placing the AI system on the market or putting it into service. Article 74 grants market surveillance authorities the right to access technical documentation and logs on request; no specific response timeframe for log production is stipulated in the Act. Regulation (EU) 2024/1689. eur-lex.europa.eu
- EU Medical Device Regulation, Article 10(8) — Manufacturers of medical devices must keep technical documentation and the EU declaration of conformity available for a period of at least 15 years after the last device has been placed on the market. Regulation (EU) 2017/745. eur-lex.europa.eu
- EU AI Act, Article 11(2) — SME simplified documentation: for small and medium-sized enterprises, including start-ups, the technical documentation referred to in paragraph 1 may be provided in a simplified manner; notified bodies must accept such simplified forms. Regulation (EU) 2024/1689. eur-lex.europa.eu
- European Commission Recommendation 2003/361/EC — Definition of micro, small, and medium-sized enterprises: micro (<10 employees, ≤€2M turnover or balance sheet); small (<50 employees, ≤€10M); medium (<250 employees, ≤€50M turnover or ≤€43M balance sheet). Referenced in EU AI Act Recital 76. eur-lex.europa.eu
- EU AI Act, Article 14 — Human oversight measures for high-risk AI systems: providers must design systems to enable natural persons to effectively oversee the system, understand its capabilities and limitations, monitor operation, and intervene or override outputs. Regulation (EU) 2024/1689. eur-lex.europa.eu
- EU AI Act, Article 27 — Fundamental rights impact assessment (FRIA): deployers that are bodies governed by public law, or private bodies providing public interest services (banking, insurance, water, gas, heating, transport, electronic communications, social protection services) must conduct and document a FRIA before deploying a high-risk AI system. Regulation (EU) 2024/1689. eur-lex.europa.eu
- EU AI Act, Article 9 — Risk management system: providers must establish, implement, document, and maintain a risk management system throughout the entire lifecycle of the high-risk AI system; includes identification, evaluation, and mitigation of known and foreseeable risks. Regulation (EU) 2024/1689. eur-lex.europa.eu
- Digital Operational Resilience Act (DORA), Article 12 — ICT-related incident record-keeping requirements for financial entities; retention and classification requirements for incident logs. Regulation (EU) 2022/2554. For AI models specifically in credit risk and other financial applications, EBA Guidelines on Internal Models (EBA/GL/2023) also apply. eur-lex.europa.eu
All EU legislative references verified against the Official Journal of the European Union. Last verified: March 2026. Legislative texts subject to amendment — monitor eur-lex.europa.eu for updates. This article does not constitute legal advice; consult qualified EU AI Act legal counsel for your specific compliance situation.
Download the Annex IV Documentation Template
A pre-structured, editable Annex IV technical dossier template — all 10 sections, guidance notes per element, sub-section checklists, version log, and a separate Instructions for Use framework. Ready to adapt for your specific AI system.
Includes: Data Documentation Template, Risk Register Template, Declaration of Conformity Draft, Post-Market Monitoring Plan Template. Used by compliance teams at 300+ organizations across Europe.
Leave a Reply